
Hace tiempo que escribí la última entrada de esta serie (que no las tengo encadenadas como con otras, pero si alguien se interesa por ellas, puede recurrir a esta búsqueda). Nuevamente debo iniciar el proceso de búsqueda de empleo. Antes de escribir al respecto de los pormenores, retos y aventuras de esta ocasión, quiero dejar algunas reflexiones sobre un par de campos en los que me interesa desenvolverme.
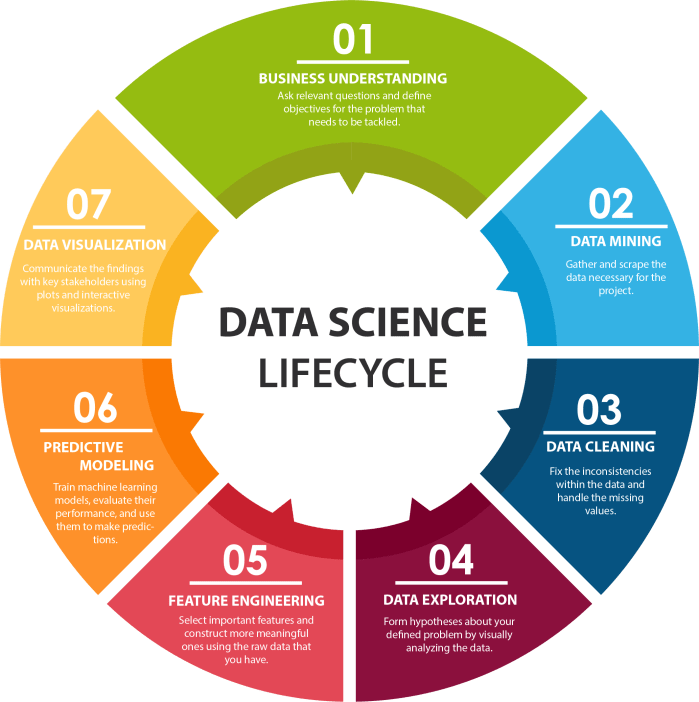
Hace unos diez años descubría lo que llamaban la «sexi ciencia del siglo XXI», que contemplaba al machine learning como una herramienta de la que podía echarse mano para poder llevar a cabo ese descubrimiento de patrones ocultos o causas a los que los grandes o pequeños conjuntos de datos debían como esencia de su comportamiento. Cinco años después leía nuevas reflexiones sobre el giro que debía darse a esta «sexi ciencia del siglo XXI» en el que se señalaban dos aspectos que un profesional de estos campos debía dominar: las estadísticas y la computación.
La primera por todo ese conjunto de herramientas y conocimientos que el analista de datos (hoy mucho mejor y más robustamente definido que ese término que me enseñaron cuando cursé la licenciatura) debe contar para poder darse una idea sobre la naturaleza de los datos, aquello que los define, su uso, potencialidades (información que de ellos puede obtenerse), relaciones y dependencias. Todo aquello que permite determinar las estructuras que podrán contenerlos, a ellos y su esencia, así como todas esas relaciones y potencialidades que les darán ese valor que su dueño ha apreciado o previsto, junto con lo necesario para que cobre vida el flujo de trabajo que materialice su ciclo de vida.
Pocos años antes de todo este movimiento de la ciencia de datos, alrededor de un lustro quizás, ya algo se cocinaba en el desarrollo de software. Comprendía lo que a muchos nos enseñaron como «programación de sistemas»– no confundir con el «desarrollo de sistemas de información» –, la ingeniería de software, y las buenas prácticas para su integración en «producción, y crecía con éxito: el concepto de DevOps.
Por otra parte, ese segundo campo que se menciona dos párrafos atrás y que debe dominarse, la computación (quizás formulado desde el punto de vista americano pero que para muchos debe incluir elementos de informática), comenzó a hacerse evidente conforme se empezó a notar que los científicos de datos debían ser algo más que actuarios o matemáticos, pues gran parte del tiempo de las actividades de éstos era lidiar con la obtención y preparación de los conjuntos de datos y luego con entregar los resultados de forma que pudieran ser integrados a producción. En un inicio esto dio lugar a una metáfora relacionada con los unicornios y a la búsqueda de científicos de datos fogueados en la informática y computación práctica. Hoy, cuando uno lee las descripciones de los empleos en los que enumeran las habilidades para un ingeniero de aprendizaje automático, y a veces también para un científico de datos, vemos que pareciera que están buscando más a todo un departamento de IT que a una persona.

Así, la importancia y preponderancia de sistematizar una ciencia que se hace de forma artesanal, llevó a la adopción del enfoque de DevOps para dar lugar a MLOps. Conforme el campo de aprendizaje automático ha venido evolucionando, viene resultando imposible que el científico de datos domine también un segundo terreno de conocimiento.
Referencias
- Bernardo Lustosa, «As machine learning evolves, we need to update the definition of ‘data scientist’«, venturebeat.com, web. Published: 2018.05.20; visited: 2024.01.26. URL: https://venturebeat.com/business/as-machine-learning-evolves-we-need-to-update-the-definition-of-data-scientist/.

