
Hay una reclutadora (de una compañía que no nombraré pues al final no viene al caso ésta) que insistentemente me había estado buscando por dos semanas para una posición como «data scientist«, al menos eso supe inicialmente. Me solicitó poder tener con ella una llamada para «platicar más del asunto» pero, pese a agendarla, incumplía el compromiso. Al final, pudimos tener esa llamada y platicamos de mi estado laboral actual, de mis pretensiones profesionales y las económicas. Mientras que lo anterior no pasa a mayores comentarios, lo menciono sólo porque en la entrada anterior no terminé de concretar la siguiente idea.
Los reclutadores son, al fin y al cabo, buscadores en un mercado que no conocen, pero que aprovechan el que la mercancía quiere ser comprada y eso les facilita su trabajo. Pasan «el changuito» al área que finalmente concretará «la compra». Son de lo más atentos y amables mientras no encuentren lo que buscan. Una vez que lo encuentran, desechan a todos los demás candidatos sin más miramientos. El problema es que, pese a lo que digan ellos, tratándose de puestos especializados, como por ejemplo data scientists o machine learning engineers, no tienen idea de lo que buscan y menos en la «identificación del talento» (como a ellos les gusta decir). Mucho menos cuando la posición implica cierta capacidad o habilidad de investigación (científica o tecnológica). Se apoyan simplemente en revisar la lista de requisitos o habilidades que el «consumidor» está buscando más los guiones que ellos ya tienen aprendidos en cuanto a identificar aptitudes o aspectos favorables de la experiencia laboral de «la mercancía» para determinar si pasa a una segunda etapa de examinación en la que ellos ya se lavan las manos.
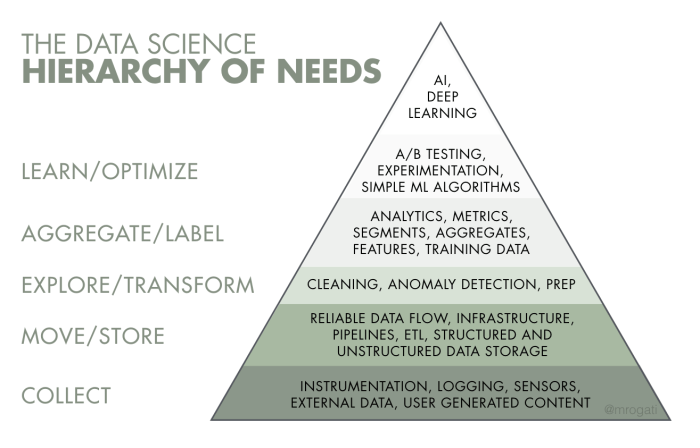
Hace unos cinco o seis años empezó el boom por la búsqueda de científicos de datos, profesión que llegaron a llamar la más sexy del siglo XXI. Personalmente, considero que el puesto o rol del científico de datos tiene más forma para un actuario que para un desarrollador de software, pero la necesidad de interactuar con el personal de IT para hacerse de insumos y publicar resultados (automatizando– o al menos facilitando –la adquisición de materia prima para trabajar, así como la integración o entrega de productos o resultados en «producción») hace que se requiera de una formación informática. Y no considero que los actuarios la adquieran en su formación (desafortunadamente, he de confesar que, por la experiencia de haber trabajado con un actuario que por habilidad o circunstancia se colocó en una posición de poder y que más que brindar soluciones generaba problemas, desde entonces «traigo a los actuarios atravesados»).
Considero que un actuario no es un informático, pese a que ellos digan que por el hecho de que les enseñen o aprendan a programar, puedan serlo. Que si un actuario puede ser un científico de datos, sí (e incluso diría que tienen mejor formación para ello que un informático), pero una libreta Jupyter, una hoja de Excel, un espacio de trabajo en R Studio o algo así, no hacen un ambiente de producción. Sólo son espacios de trabajo o de investigación. Espacios que resultan artesanales y lentos para lo que una empresa «data driven» pretende. Y, al final, si bien esto puede ser el 80 por ciento del trabajo del data scientist es sólo el 20 por cierto del entorno en el que se moverá, parafraseando a Pareto.
No pasó mucho tiempo en que lo anterior fuera percibido y se hiciera el comentario de que un científico de datos con las habilidades y conocimientos suficientes para hacer ciencia de datos e integrar resultados en un entorno productivo informático fuese visto como algo muy difícil de conseguir. Una figura mítica que podría no encontrarse y de donde surgió la metáfora con los unicornios. De la misma forma como en el entorno de DevOps se concibe al «full-stack engineer» (que en la misma medida de estas reflexiones, vemos que las habilidades que para éste se piden parecen ser la suma de todo un departamento de IT). Así, empezó a verse el rol de los científicos de datos como algo para lo que se requiere más preparación de la inicialmente estimada. La dificultad de conseguir en una misma persona las habilidades de dos mundos muy diferentes (el mundo formal de las matemáticas, la estadística, la investigación de operaciones, finanzas, inventarios, etcétera; y del mundo tecnológico de la informática y la computación) propició el desarrollo de muchas librerías y paquetes que facilitan las operaciones formales haciendo que el interés por la ciencia de datos menguara un poco. A esto, sumemos lo que poco en poco se fue notando: el científico de datos dedicaba más tiempo al DevOps que a la ciencia.
En este instante, ahora que el mundo aparentemente sale de la pandemia del coronavirus, un enorme interés se ha volcado en la inteligencia artificial y en el aprendizaje automático (ML, por machine learning). Y, similarmente a lo mencionado en el párrafo previo, la necesidad de integrar resultados de ML en el entorno de producción de la empresa, ha hecho que poco a poco se conceptualizara el rol de la integración y ambientación de lo que se requiere en ML y que se distinguiera del de investigación (algo que creo ha fallado en la ciencia de datos), de forma que desde el año pasado ya se habla de roles muy específicos para estos dos aspectos, conocidos ya como MLops y MLmodels.
Así entonces, con respecto al inicio de esta entrada, mientras que dejé pasar el ofrecimiento, la reclutadora me indicó que le gustaría dejarme en su cartera de candidatos y su bolsa de trabajo (donde por cierto, primera vez que veo que por el simple hecho de estar en una bolsa de trabajo hay ciertos beneficios, como si se tratara de una membresía) y, según ella, en diciembre me buscarían de nuevo para platicar nuevamente pues me decía que mi perfil no era muy común, y ciertamente así lo creo. Aunque no podría ser un unicornio, pues me falta un mayor conocimiento y práctica de las herramientas formales que se requiere para cumplir con lo que el perfil demanda.
No puedo negar que inicialmente la ciencia de datos llamó mi atención como para orientarme hacia ella (y de hecho apliqué por algunas vacantes al respecto, que me dieron muy buena idea del perfil que se busca) pero hoy ya la veo un poco aburrida. La experiencia vivida desarrollando la infraestructura de Eva, me mostró que tengo facilidad e interés en ello, así que desde entonces me auto nombré «machine learning infrastructure engineer» (título que hoy es muy solicitado en USA pero que en México apenas comienza a identificarse). Dado el enorme interés por la AI y el ML que empezó a sentirse desde mediados de año, y más en el último cuarto, comencé a buscar nuevas oportunidades laborales.

