
Entrando a los detalles sobre algunos ciclos en particular (ver post previo por enlaces a otros ciclos que he llegado a describir), uno de los más recientes que me ha tocado adoptar es el relacionado a los datos y que de hecho no tiene mucho de haber sido formulado1,2. Tras su concepción, otros autores han aportado en el refinamiento de la definición y la estructura del ciclo. Curiosamente, la definición inicial indicaba la ausencia de enlaces cíclicos entre las etapas que describía pero no las negaba, reconocía la posibilidad o necesidad de que entre cada etapa hubieran bucles y presentaba más un flujo lineal que un ciclo, enfocándose en la importancia del flujo principal para resaltar los diferentes estados que el conjuntos de datos adoptaba.
- El ciclo de vida de los datos inicia con su generación, que puede ser mediante un proceso que los conforma (los crea o calcula) o derivados de la extracción de éstos a partir de una entrada.
- Tras su obtención viene una posible recolección, ya que hay casos en los que no es posible procesarlos inmediatamente (por su cantidad o por el tiempo que puede tomar recolectarlos). Aunque la recolección puede no ser necesaria en muchos casos, es mucho más factible su presencia en casos de Big Data.
- Tras la recolección viene el procesamiento (filtrado, extracción, preparación, arreglo). Toda aquella acción destinada a la manipulación de los datos para su almacenamiento o para que puedan ser procesados. El almacenamiento puede darse antes o después de su procesamiento. Conservando los datos originales o aquellos derivados del proceso. Para muchos, este «procesamiento» puede sugerir la actividad principal (un «proceso de negocio», procedimiento o algoritmo alrededor del cual gira el objetivo del procesamiento) pero, como se indica al inicio de este punto (lo colocado entre paréntesis) nos referimos a acciones de limpieza y de manipulación preparatorias.
- A lo largo de todo esto (y otros pasos aún no indicados), la administración del ciclo y del conjunto de datos está siempre presente. Comprende la gobernanza del ciclo y sus derivados.
- A partir de los datos ya preparados (recuperados de algún medio o entorno de almacenamiento, o de un flujo) se procede con un análisis, que consiste en todas esas acciones destinadas a su estudio para derivar datos, información, intuición o conocimiento nuevos. Puede ser referido también como el verdadero «procesamiento de los datos», a fin de resaltar la diferencia con el procesamiento anteriormente mencionado, pero en el terreno de la ciencia de datos es más común referirse a esto como una actividad de estudio que puede ser preliminar (de exploración) o ya enfocada a la generación de un modelo de comportamiento o pronóstico.
- Con los resultados que el análisis provee, pasamos a la presentación de resultados. Lejos han quedado esos días donde esta presentación era considerada, principalmente, como aquella donde el producto principal eran reportes. Hoy, la facilidad de presentación en forma de gráficas, suele ser llamada visualización (abarcando desde simples gráficas de curvas o histogramas, hasta infografías). Los reportes son ya un complemento secundario.


Si bien esta primera conceptualización (lineal) no contempló algunas algunas otras que otros autores han añadido, como el archivamiento de los datos (archives) y su eventual borrado (por mencionar los que creo son universales y los más importantes), cubre las principales etapas de este ciclo. Pero, las etapas pueden variar en número o cambiar de nombre de acuerdo a las actividades propias de cierta industria o área de conocimiento.
Curiosamente, muchos diagramas al respecto son presentados en forma como se muestran las dos imágenes previas, donde no se puede observar explícitamente un ciclo. Las presentaciones son variadas, desde las lineales o centralizadas, a algunas de cascada,

orientadas a una tecnología en particular,
las que parecen dar la ilusión de un ciclo,
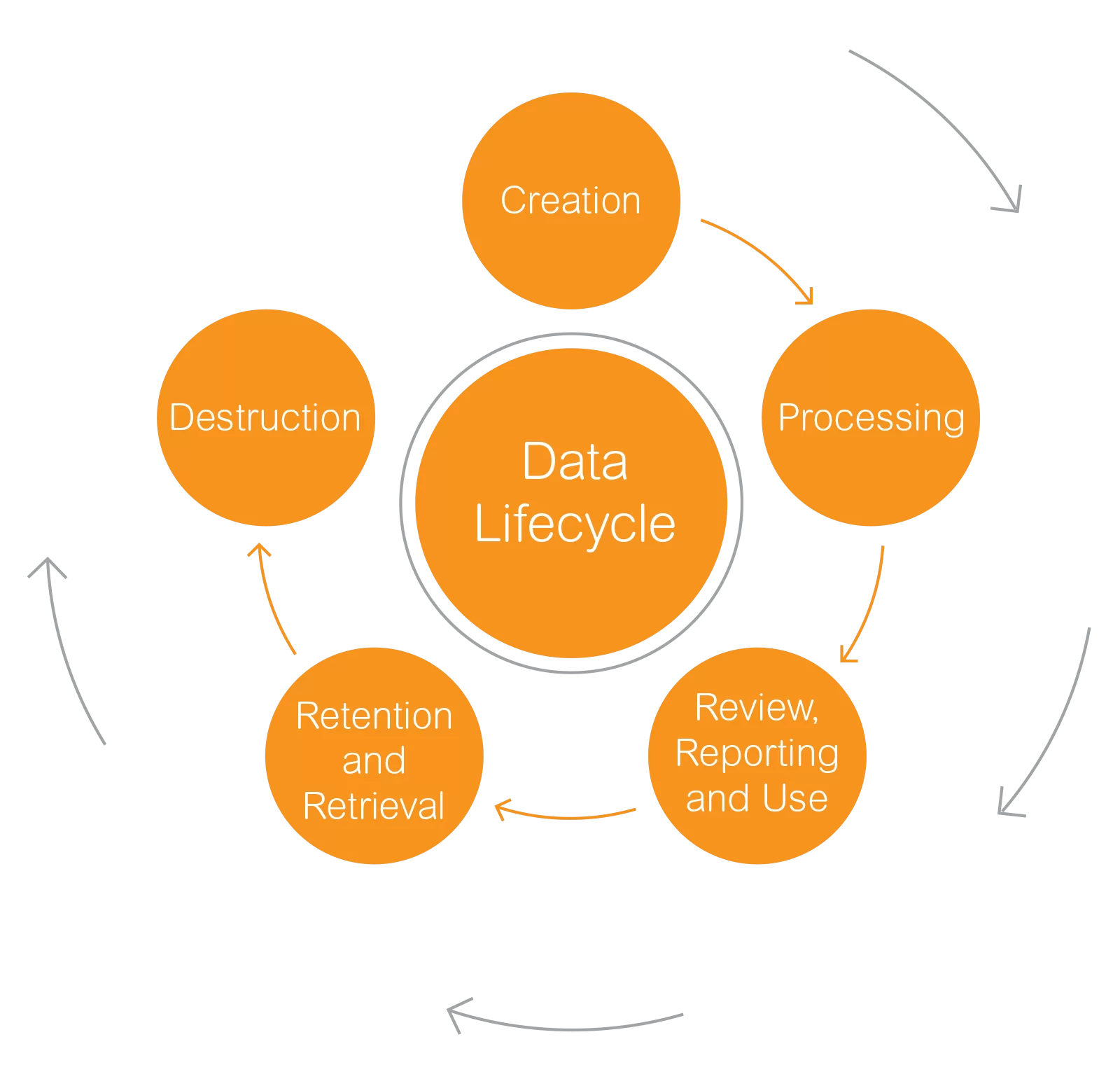
hasta aquellas que verdaderamente lo muestran.

Como sea, creo que es importante considerar que si bien estas descripciones llevan en su título la palabra «ciclo», no es importante el denotar explíticitamente el aspecto cíclico implicado, es decir, pensando que de los datos destruidos (o abandonados a un archivo muerto) surgirán nuevos datos. Sí, en algunos ciclos esto es importante para hablar de la naturaleza cíclica del fenómeno (como el ciclo del agua, por ejemplo) pero recordemos otros donde el el estadío final no llega directamente al inicio del otro, como puede ser el de la vida humana. A nuestra muerte, la materia prima de nuestro cuerpo no se usa para generar nuevos seres humanos. Nuestro ciclo de vida lo ramificamos cuando nos encontramos en nuestra etapa reproductiva. Ahí es donde un nuevo ciclo da inicio, dándonos la oportunidad de dirigir el camino del nuevo.
En el caso de los datos, de un archivo muerto puede surgir, via su exploración, alguna correlación o vislumbrarse un nuevo uso pero, también el liberar el espacio ocupados por datos añejos puede permitir disponer de recursos para iniciar exploraciones con nuevos datos. En el terreno de los datos, seguramente podemos encontrar varios puntos donde iniciar un nuevo ciclo.
Referencias
- Jeannette M. Wing, «The data life cycle«, Data Science Institute, Columbia University, web. Published 2018.01.23; visited: 2024.03.16. URL: https://datascience.columbia.edu/data-life-cycle
- Jeannette M. Wing, «The Data Life Cycle», Harvard Data Science Review, MIT Press. Published: 2019.07.01; visited: 2020.12.07. DOI: 10.1162/99608f92.e26845b4. ISSN: 2644-2353. URL: https://hdsr.mitpress.mit.edu/pub/577rq08d/release/3.

