
 |
|||
 |
PlaidML es un compilador de tensores de código abierto. Es una alternativa y brinda la posibilidad de sacar provecho a una amplia gama de unidades de procesamiento para acelerar el cálculo y procesamiento en labores de cómputo intensivo. | ||
Introducción
La descripción del proyecto, en su repositorio en GitHub, se traduce como: «PlaidML es un marco de referencia (framework) para hacer que el aprendizaje profundo funcione donde sea.»1 Por el momento, esta descripción empata mejor con la idea de que se trata de una biblioteca de funciones que permite explotar una GPU, a eso de que es un «compilador de tensores.» Conforme avance en la compresión de cómo es que todo esto funciona, ya iré mejorando o ajustando esta descripción. De cualquier modo, para quien ya conoce del tema, queda la descripción de fondo que se provee en los documentos de este proyecto1.
Un punto interesante es el que se trata de una tecnología que fue desarrollada por una startup que adquirió Intel2 y que posteriormente se hizo open source.
Instalación
macOS
La instalación en macOS se ha hecho esencialmente como se describe en la documentación, salvo por algunos cambios que aquí se describen.
Primeramente, en este caso estoy haciendo uso de conda para el manejo de los entornos virtuales.
$ conda create --name pml python=3.6
$ conda activate pml
(pml) $ pip install -U plaidml-keras
(pml) $ plaidml-setup
Tras configurar la instalación (ver más abajo sobre detalles en la configuración hecha tras ejecutar este último comando) se procedió con algunas pruebas. La documentación indica que esto puede hacerse de la siguiente forma:
(pml) $ pip install plaidml-keras plaidbench
(pml) $ plaidbench keras mobilenet
Sin embargo, la ejecución del script mobilenet y mobilenet_v2 produce un error (aquí ilustrado haciendo uso de la CPU del equipo, pero igual ocurre con la GPU):
(pml) $ plaidbench keras mobilenet_v2
Running 1024 examples with mobilenet_v2, batch size 1, on backend plaid
INFO:plaidml:Opening device "llvm_cpu.0"
'str' object has no attribute 'decode'
Set --print-stacktraces to see the entire traceback
«Gugleando» sobre el problema leeremos que hay quienes indican que se solución haciendo un downgrade de H5py. En mi caso no ha funcionado. Obtengo un error al tratar de instalar versiones anteriores al momento de su compilación en la instalación. Afortunadamente, plaidbench funciona con otros ejemplos (ver ejemplos en la sección Uso).
Versión
Salvo que se indique otra cosa, lo aquí indicado aplica para la versión de PlaidML.
$ pip freeze
...
plaidbench==0.7.0
plaidml==0.7.0
plaidml-keras==0.7.0
...
Uso
Configuración
Antes de hacer uso de PlaidML, es necesario establecer la configuración de la generación de código, cosa que se logra ejecutando el script plaidml-setup. Este script identifica la CPU y GPU disponibles, y permite habilitar características que aún están en prueba (experimentales, como OpenCL para el uso de la GPU). La siguiente imagen muestra el diálogo con este script.
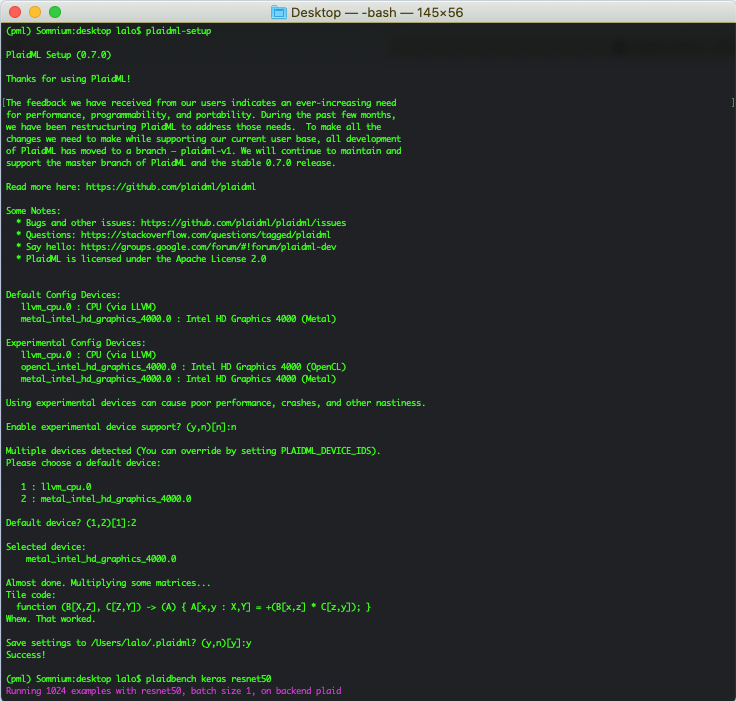
Al respecto del monitoreo de la GPU, ver estas entradas en el blog (1, 2, 3).
Ejemplos de programas incluidos con el framework
El framework incluye algunos programas que pueden usarse para validar el funcionamiento de los componentes y el hardware disponible. Aquí vemos los resultados con resnet50 haciendo uso de la GPU.
(pml) $ plaidbench keras resnet50
Running 1024 examples with resnet50, batch size 1, on backend plaid
INFO:plaidml:Opening device "metal_intel_hd_graphics_4000.0"
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels.h5
102858752/102853048 [==============================] - 21s 0us/step
Compiling network... Warming up... Running...
Example finished, elapsed: 4.138s (compile), 306.063s (execution)
-----------------------------------------------------------------------------------------
Network Name Inference Latency Time / FPS
-----------------------------------------------------------------------------------------
resnet50 298.89 ms 0.00 ms / 1000000000.00 fps
Correctness: PASS, max_error: 3.024923216798925e-06, max_abs_error: 7.748603820800781e-07, fail_ratio: 0.0
y haciendo uso de la CPU.
(pml) $ plaidbench keras resnet50
Running 1024 examples with resnet50, batch size 1, on backend plaid
INFO:plaidml:Opening device "llvm_cpu.0"
Compiling network... Warming up... Running...
Example finished, elapsed: 9.904s (compile), 452.967s (execution)
-----------------------------------------------------------------------------------------
Network Name Inference Latency Time / FPS
-----------------------------------------------------------------------------------------
resnet50 442.35 ms 436.42 ms / 2.29 fps
Correctness: PASS, max_error: 1.2038562090310734e-05, max_abs_error: 1.4454126358032227e-06, fail_ratio: 0.0
Otros ejemplos
Ejemplos de uso con programas desarrollados ex professo u obtenidos de otras fuentes. El código fuente de los programas usados en esta sección, a menos que sea explícitamente mostrado aquí o incluida alguna liga a éste, puede ser visto en el repositorio que ha sido creado en GitHub.
En mi Mac, VGG-19 entrega las siguientes resultados: 55.540786266326904 segs. usando la GPU, 75.89665937423706 usando la CPU.
Referencias
- «About«, github.com, web. Visited: 2021.03.18. URL: https://github.com/plaidml/plaidml.
- Choong Ng, «Reintroducing PlaidML«, Intel, blog. Published: 2018.10.26; visited: 2021.0.16. URL: https://www.intel.com/content/www/us/en/artificial-intelligence/posts/reintroducing-plaidml.html.
- «Installation Instruction«, PlaidML, web. Visited: 2021.03.18. URL: https://plaidml.github.io/plaidml/docs/install.
|
© Todos los derechos reservados. Dr. Eduardo René Rodríguez Avila |
Creación: 2021.03.16 Última actualización: 2021.04.01 |
|||
| El contenido de este sitio puede ser copiado y reproducido libremente mientras no sea alterado y se cite su origen. Marcas y productos registrados son citados por referencia y sin fines de lucro o dolo. Todas las opiniones son a título personal del o los autores de éstas y, salvo sea expresado de otro modo, deben considerarse como registro y expresión de la experiencia de uso de aquello que es tratado. Para conocer más sobre la posición de privacidad y responsabilidad de lo que se presenta en este sitio web y como ha sido obtenido, consulte la declaración al respecto. | |||||

