
Supongamos que tenemos un modelo de programación lineal que resuelve:

Normalmente encontramos este tipo de modelos para resolver problemas de regresión u optimización continua. Al ser continuos, estos modelos no pueden resolverse de una forma en la que podamos considerarlos para fines de clasificación y que nos permitan crear, por ejemplo, una matriz de confusión para comparar su rendimiento con clases de datos reales. Para ello necesitamos considerar su solución desde un punto de vista de valores discretos.
Así, si queremos clasificar los puntos de un plano como pertenecientes a una clase 


Supongamos que tenemos el conjunto de datos:

Queremos hallar ![w = [a,b]](https://s0.wp.com/latex.php?latex=w+%3D+%5Ba%2Cb%5D+&bg=ffffff&fg=424242&s=0&c=20201002)


Obsérvese que lo que hemos empezado a plantear como «bien definido» nos lleva implícitamente a considerar esa naturaleza discreta ya mencionada y que manifestamos en nuestra restricción con la condición «
A fin de ilustrar mejor la idea, consideremos la representación de nuestro conjunto de datos en un espacio donde 

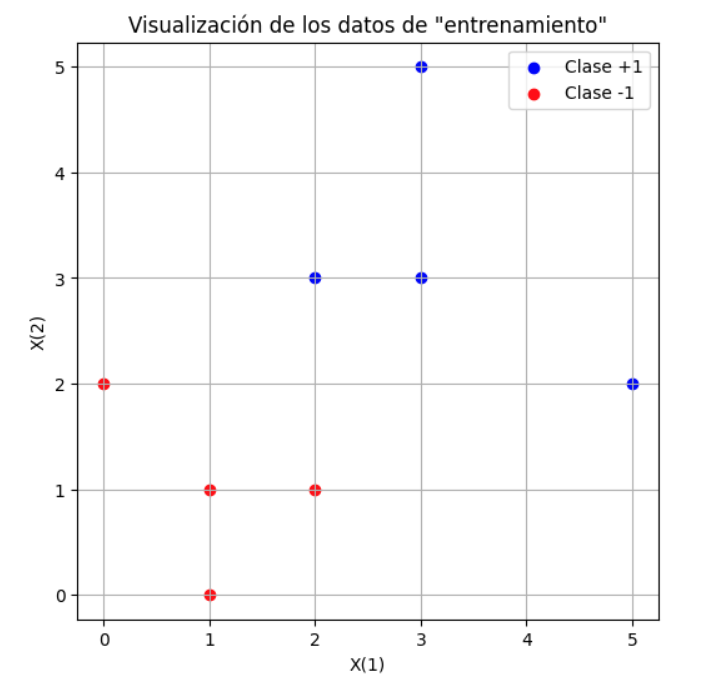
Idealmente, podríamos trazar una línea que nos permitiera separar las regiones en las que se ubican los datos de 

Lo que nos sugiere que el problema tiene una solución y es posible separar ambos conjuntos de datos. Sin embargo, cuando usamos la programación lineal para separarlos con:

Lo que se demanda no es meramente una separación sino una determinada (mínima distancia) por cada punto del híper plano (recordemos que estamos trabajando al final con cantidades discretas y tres dimensiones) de manera que la desigualdad se satisfaga. No es suficiente decir «que el ‘punto’ está del lado correcto»; deben estar separados por una franja marginal unitaria.
Por cada punto 


y por cada punto de la clase 

Esto genera la franja marginal entre
Para hacer frente a esta restricción, reformulamos nuestro modelo con variables de holgura, lo que permite puntos dentro del margen o incluso mal clasificados, a cambio de minimizar los errores totales.

Y así, agregamos la variable 

donde:

Así, si tenemos 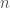

Aunque el modelo «duro» (nuestra primera versión) falló con el margen, al resolver el modelo de holgura, veremos que podemos encontrar una solución factible sin errores reales. Esto sugiere que existe un límite válido, pero el anterior era demasiado estricto al exigir un margen exacto.
Así entonces, el margen lineal es:

Un Jupyter notebook exponiendo esto (en inglés) más la implementación en Python junto con el uso de los solucionadores y optimizadores de modelos de programación lineal, está disponible en el hiperenlace al inicio de este párrafo.

