
![]() La sexta semana del MOOC Mining Massive Datasets tuvo unas 3 horas de video lecturas. Dos tercios de las lecturas se enfocaron a dos temas de machine learning: support vector machines y decision trees. En la parte de los árboles de decisión se revisó algo interesante entorno al concepto de «ganancia de información» (information gain).
La sexta semana del MOOC Mining Massive Datasets tuvo unas 3 horas de video lecturas. Dos tercios de las lecturas se enfocaron a dos temas de machine learning: support vector machines y decision trees. En la parte de los árboles de decisión se revisó algo interesante entorno al concepto de «ganancia de información» (information gain).
La ganancia de información es la que se obtiene de una variable aleatoria X de la observación que sobre otra variable aleatoria A se tiene cuando esta adquiere un valor, en otras palabras la reducción de la entropía de X alcanzada por el aprendizaje del estado de la variable A. En términos generales la ganancia de información esperada es el cambio en la entropía 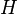 de un estado a otro por un atributo a:
de un estado a otro por un atributo a:


El último tercio de las video lecturas se dedicó al tema del algoritmo MapReduce. De este tema se empezó por revisar los costos computacionales asociados al uso de aquello que esté soportando este algoritmo, esencialmente costo de comunicaciones y costo de procesamiento.
